Part 3: Experiments
Experiment 1: MNIST Logistic Regression
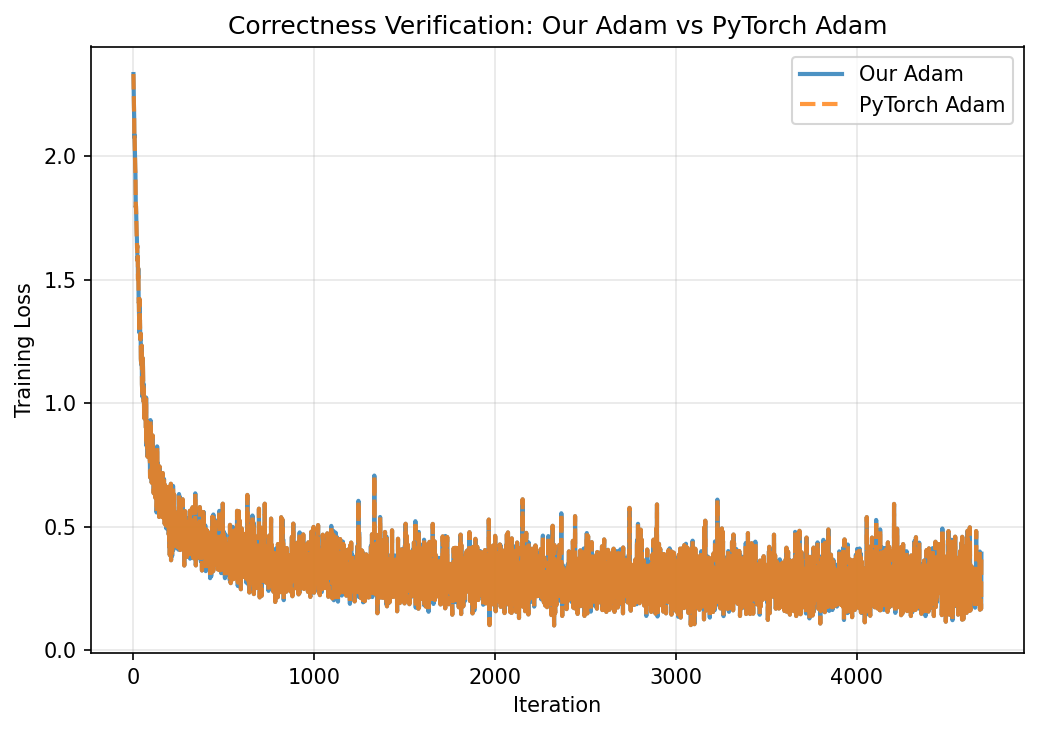
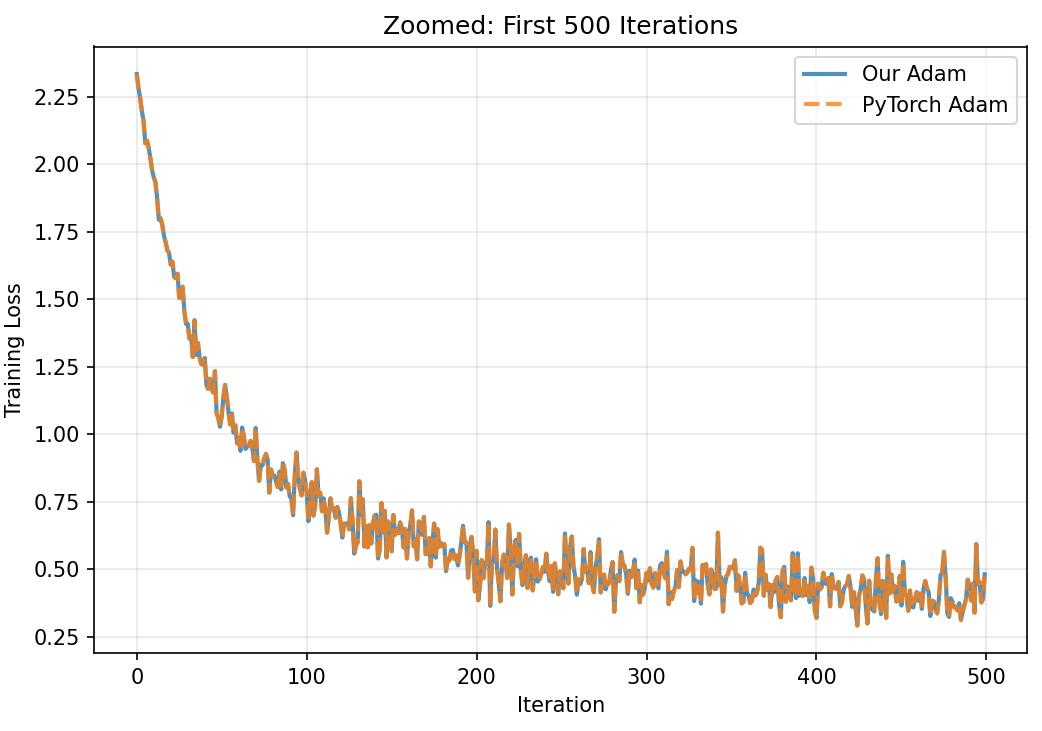
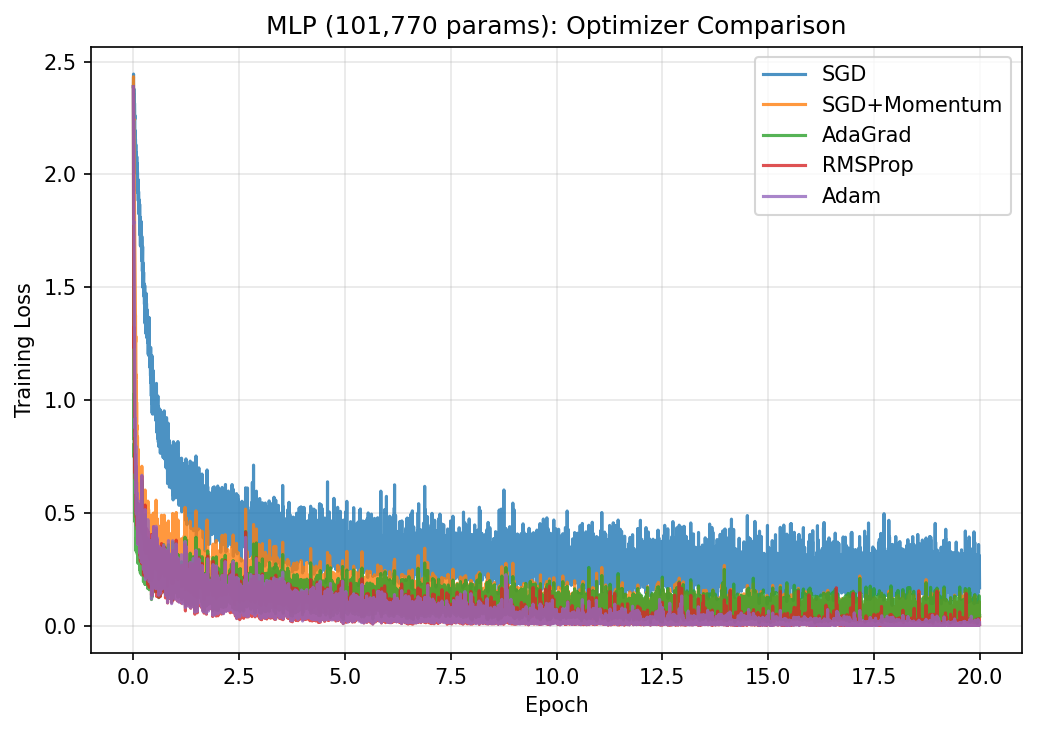
Reproducing Section 6.1 of the paper: 5 optimizers, 40 epochs, same starting weights
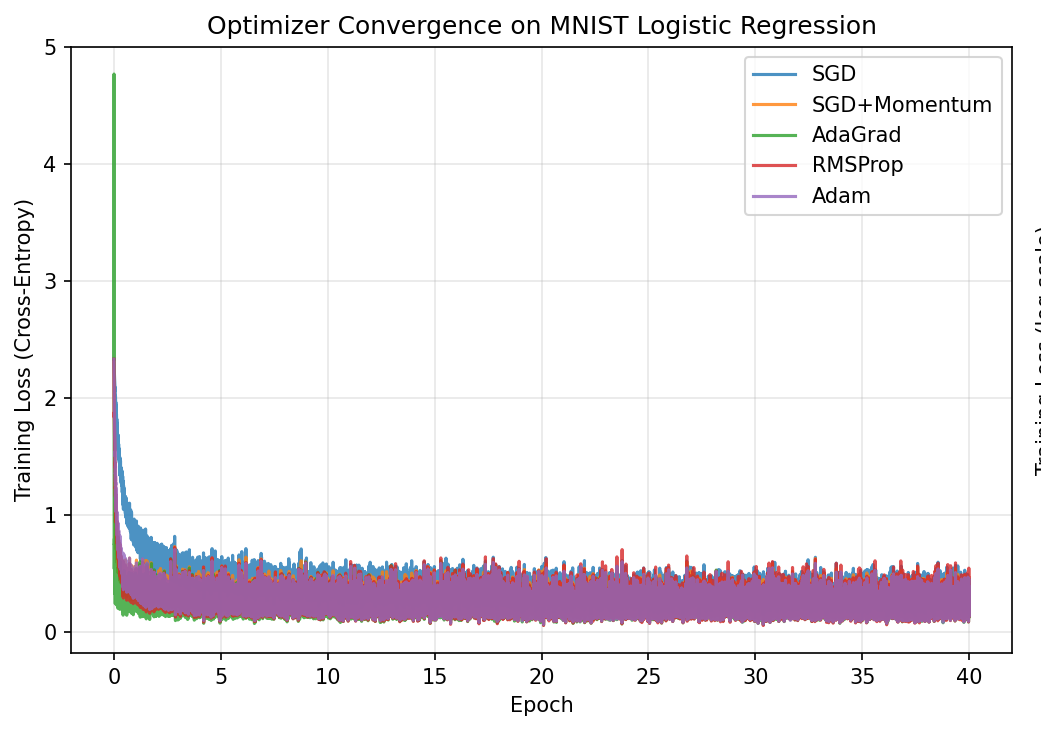
Training loss vs epoch (linear scale)
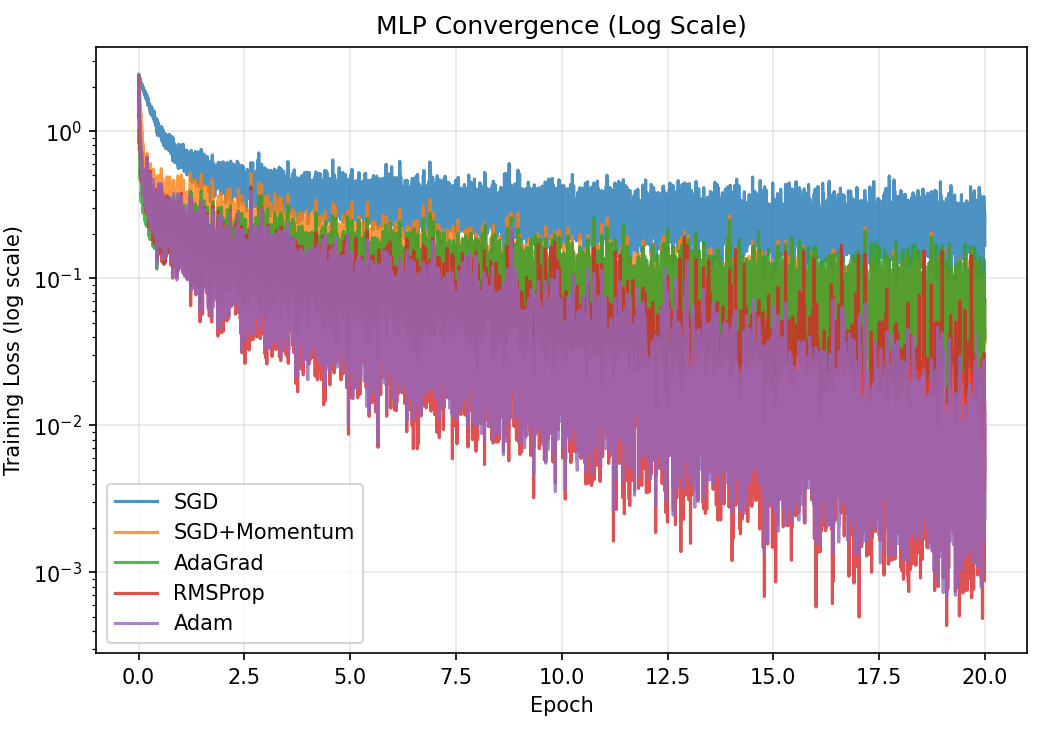
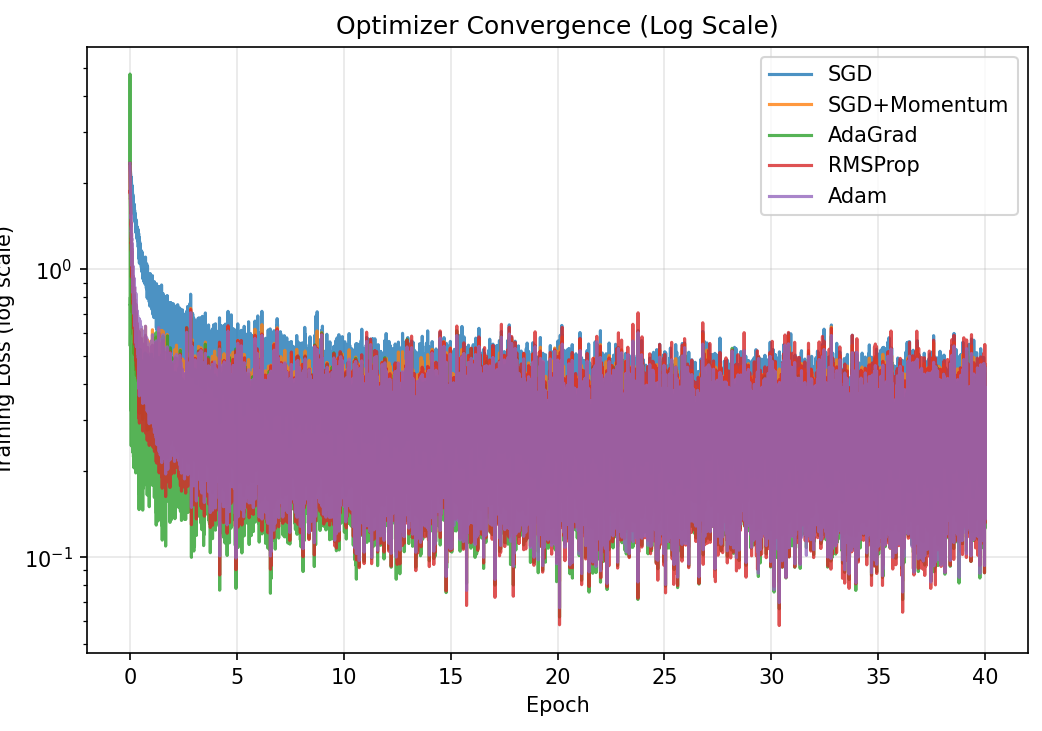
Training loss vs epoch (log scale; stretches out differences at the bottom)
Setup: 60,000 MNIST images (28x28 pixels, 784 features), 10 digit classes. Minibatch size 128. All 5 optimizers start from the same random initial weights. Logistic regression: $\hat{y} = \text{softmax}(XW + b)$, cross-entropy loss. Total: 7,850 parameters.
| Optimizer | Test Accuracy | Final Loss |
|---|---|---|
| SGD | 91.58% | 0.321 |
| SGD + Momentum | 92.36% | 0.274 |
| AdaGrad | 92.72% | 0.264 |
| RMSProp | 92.65% | 0.260 |
| Adam | 92.69% | 0.258 |
Key Finding
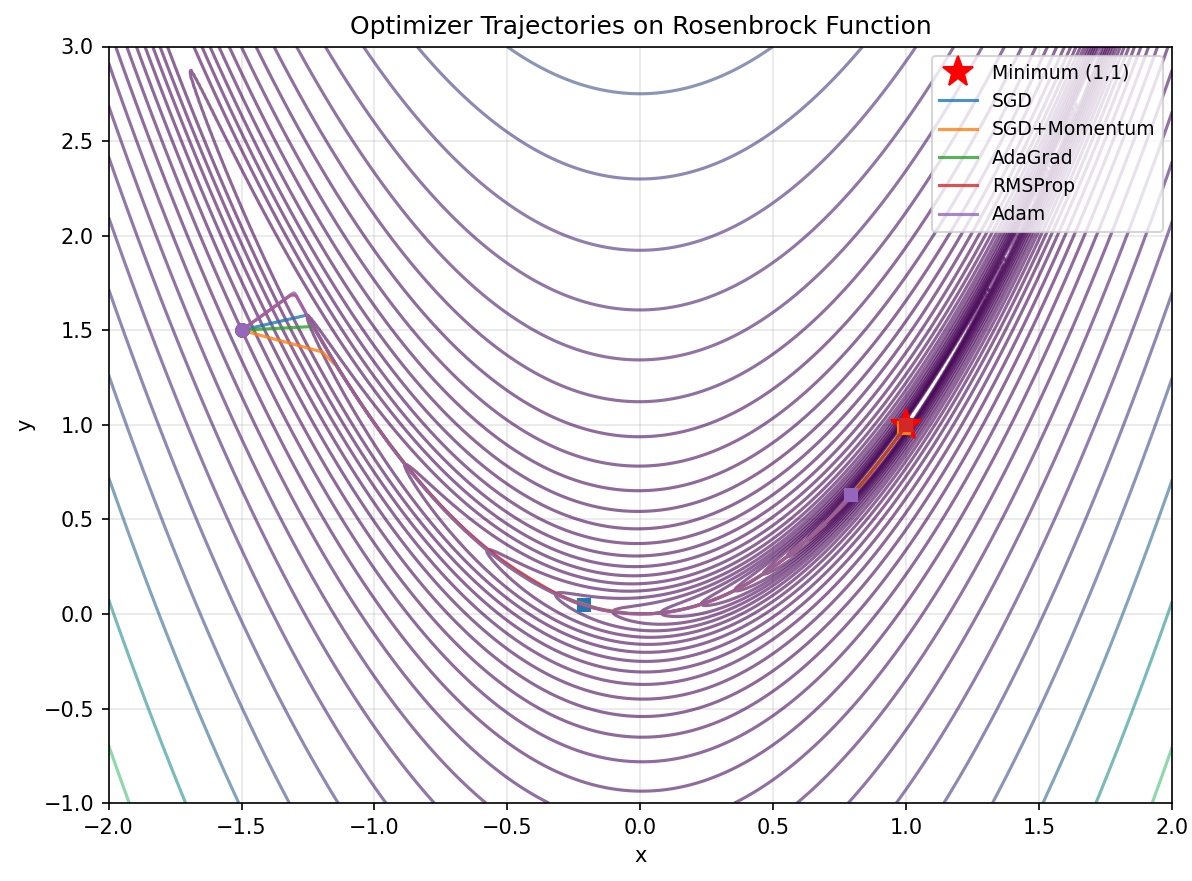
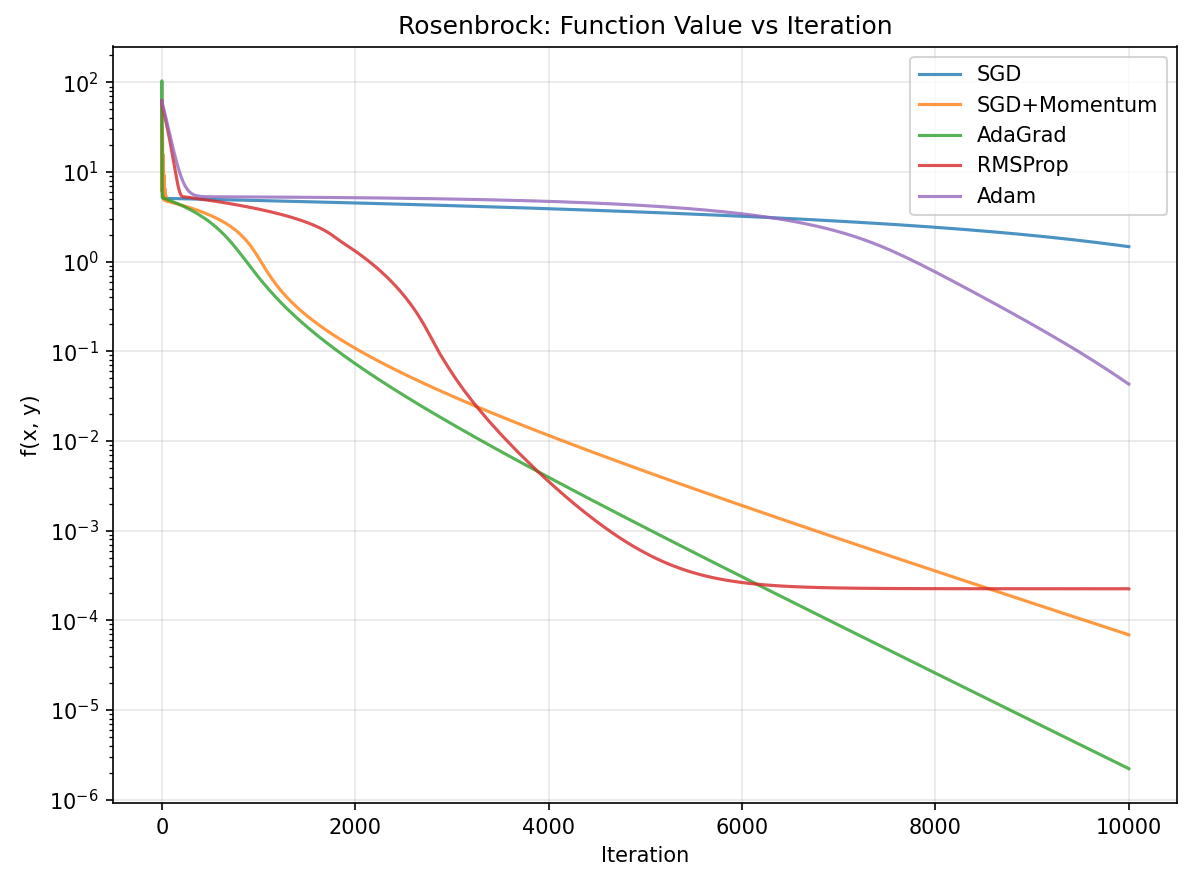
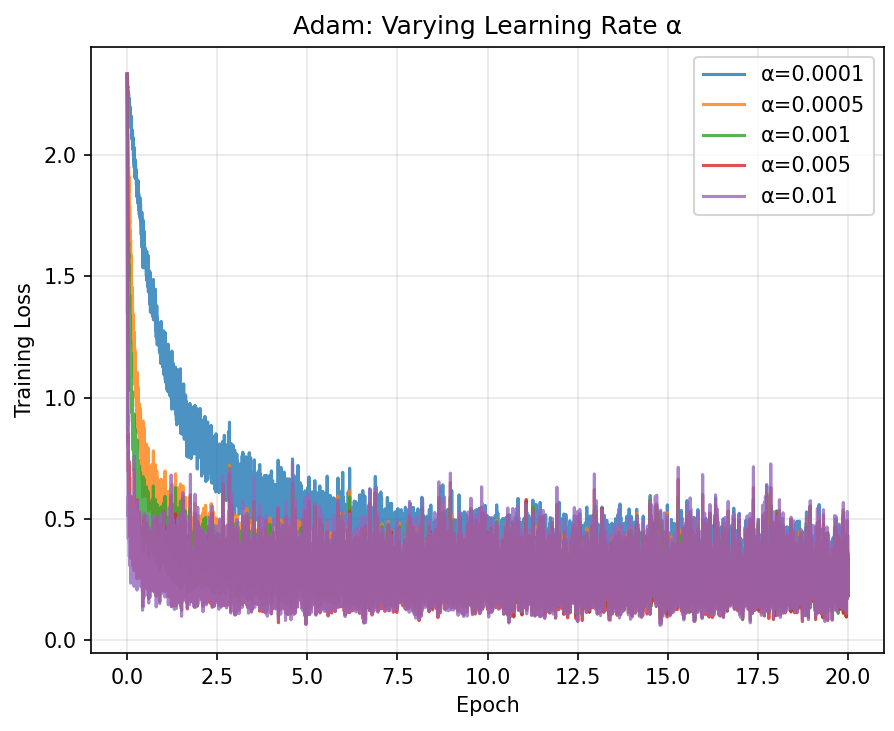
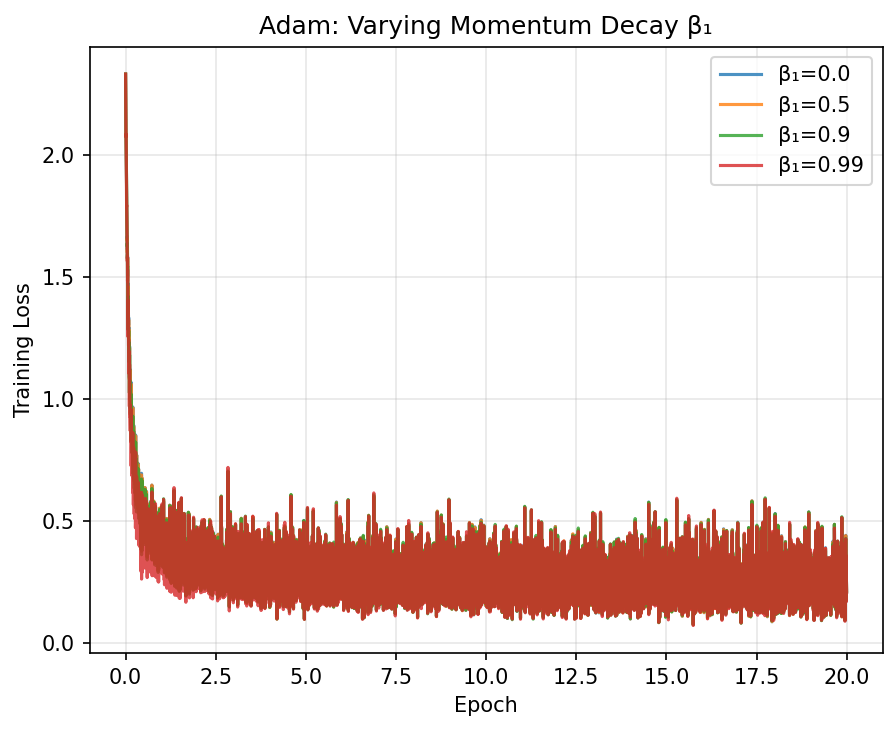
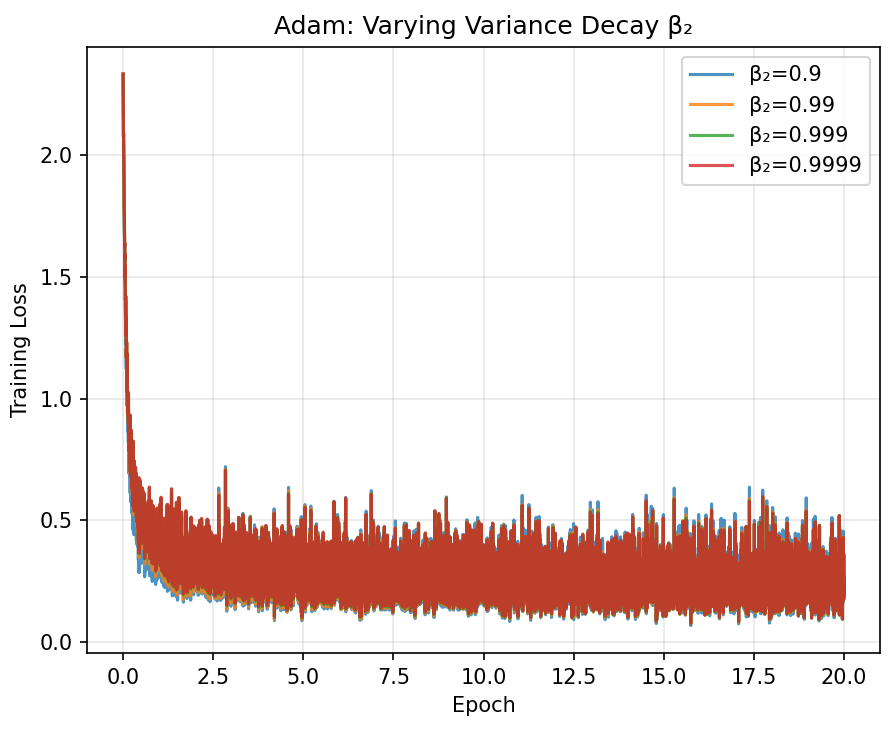
All adaptive methods beat plain SGD, consistent with the papers trends. The differences between Adam, AdaGrad, and RMSProp are small here because logistic regression is a convex problem. Adam and Momentum converge fastest in the early epochs.